Docker 容器日常巡检关键点总结
**【导读】本文对Docker容器日常巡检工作进行了整理,提供排查方法和排查思路,帮助大家学会尽快发现问题,解决问题。《Kubernetes 日常巡检》可点击标题阅读。【作者】曹如熙,**高级运维leader,具有超过十年的互联网运维及五年以上团队管理经验,多年容器云的运维。
1 docker/podman ps查看容器状态
Docker/podman ps -a 查看容器状态STATUS:
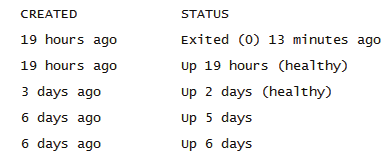
Exited(0):表示容器正常退出Exited(其他数字):容器异常退出,需要通过log 查看原因Up:容器在运行状态Up(Paused):容器暂停Up(healthy):容器监听健康
Up(unhealthy):容器监听异常
2 健康检查—HealthCheck一些参数需要docker 17.05以上支持
2.1 通过docker run或者dockerfile添加健康检查
例如:docker run –name=nginx –health-cmd=”curl –silent –fail localhost/ || exit 1” –health-inter-val=30s –health-retries=3 –health-timeout=10s –start-period=60s nginx:latest–interval:
两次健康检查的间隔,默认为 30 秒–timeout: 健康检查超时时间,,默认 30 秒–retries: 连续失败次数,默认 3 次。–start-period: 启动的初始化时间,默认 0 秒–health-cmd: shell和exec 格式,取命令的返回值结果0表示成功,1表示失败
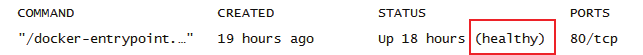
STATUS, healthy表示健康unhealthy表示不健康reserved保留值,不适用
2.2 输出健康检查状态
docker/podman inspect –format ‘‘ 容器名| python -m json.tool

输出healthy表示健康,用户可以编写脚本监控容器状态做报警
3 docker stats查看容器状态

可以通过docker stats查看容器的cpu, 内存,网络,IO的使用情况
4 通过第三方工具监听容器
这里主要介绍prometheus+grafana+cadvisor
4.1 prometheus介绍
prometheus通过node-exporter收集node主机的信息
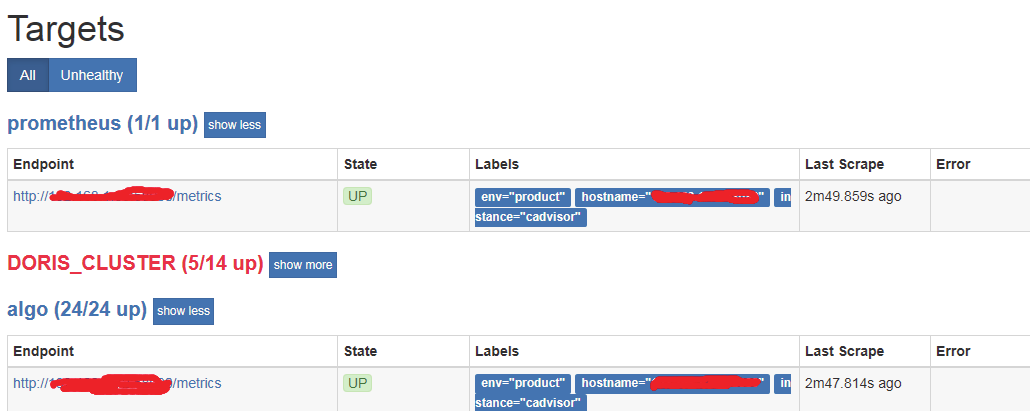
可以看到up状态和unhealthy状态的node节点主机Unhealthy表示node节点node-exporter异常Prometheus是一款强大的第三方工具,除了docker容器监控,还支持mysq,数据仓库,Hadoop,k8s 等开源系统
4.2 cadvisor介绍
Google的开源cadvisor,帮助收集,监听容器的status和数据,主要是CPU, 内存,FS,网络等usage
4.3 grafana介绍
Grafana作为展示prometheus和cadvisor的数据,也可以实现自定义规则报警。(可以去grafana官网搜寻需要监控的模板)
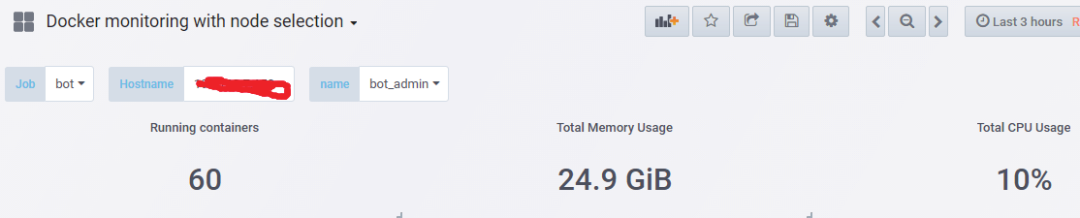
可以通过dashboard展示node主机上的所有容器通过panel,metrics自定义需要收集的容器数据
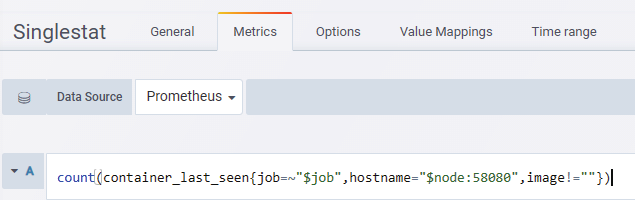
通过自定义规则统计需要收集的容器数据,也可以统计宕机状态的容器Grafana支持自定义报警功能
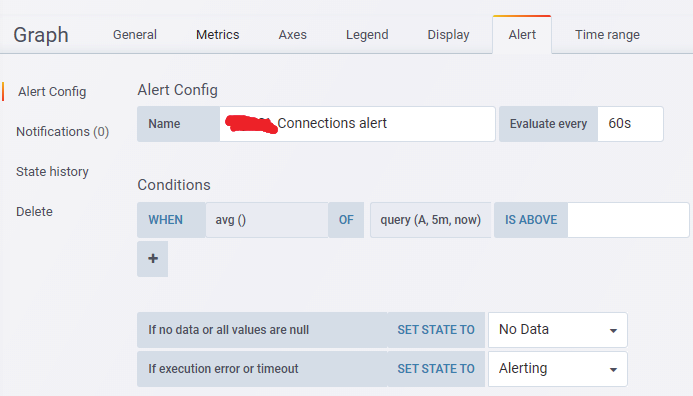
如果是大量的容器监控报警,建议使用alertmanager做报警
5 docker容器的日志检查
Docker的日志分为两类,一类是 Docker引擎日志;另一类是容器日志。引擎日志一般都交给了系统日志。容器日志可以理解是运行在容器内部的应用输出的日志。默认情况下,docker logs显示当前运行的容器的日志信息,内容包含 STOUT(标准输出) 和 STDERR(标准错误输出)。日志都会以 json-file的格式存储于 /var/lib/docker/containers/<容器id>/<容器id>-json.logCRIO的日志,存放在/var/log/containers/通过docker/podman logs命令查看容器的日志

查看最近1小时日志docker/podman logs –since 60m容器名
查看某时间段日志docker/podman logs -t –since=”” –until “” 容器名
建议:docker/podman run时候,日志文件-v到宿主机上,docker/podman run -d –name xxx -v /opt/log:/log xxx:latest通过elk去抓取宿主机上的日志,尽量不要通过docker logs去检查容器日志。除了docker容器,本文也向大家介绍kubernetes的日常巡检。